FEATURED VIDEO
Steps to Follow to Comply With the SEC Cybersecurity Disclosure Rule
Mandiant/Google Cloud's Jill C. Tyson offers up timelines, checklists, and other guidance around enterprisewide readiness to ensure compliance with the new rule.

You can't thinking about inclusion in the workplace without first understanding what kinds of exclusive behaviors prevent people from advancing in their careers.
Mandiant/Google Cloud's Jill C. Tyson offers up timelines, checklists, and other guidance around enterprisewide readiness to ensure compliance with the new rule.
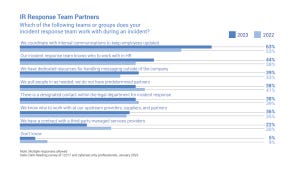
Dark Reading research finds increased collaboration between security incident responders and groups within the HR, legal, and communications functions.
Ask The Experts
MORE FROM ASK THE EXPERTS