Keep up with the latest cybersecurity threats, newly discovered vulnerabilities, data breach information, and emerging trends. Delivered daily or weekly right to your email inbox.
CVSS as a Framework, Not a Score
The venerable system has served us well but is now outdated. Not that it's time to throw the system away; use it as a framework to measure risk using modern, context-based methods.
7 Min Read
For more than 15 years, vendors have used the Common Vulnerability Scoring System (CVSS) rating system to describe the severity and scope of security flaws. The familiar 0–10 scoring format has served us well, but it no longer reflects the way modern networks and applications are built, maintained, and attacked. Something with more context, depth, and flexibility is needed to show where companies are at business risk.
That said, we shouldn't ignore the body of work that the CVSS represents. Instead, we should leverage the CVSS as a framework for measuring risk using modern, context-based methods.
What Worked Then Doesn't Work Now
Adopted in 2005, CVSS is used by the National Institute of Standards and Technology to assign security flaws a numerical rating from 0 to 10 describing their risk and severity. Vulnerabilities are graded on factors such as how the vulnerable component is exposed (for example, if it can be attacked remotely or requires local access), how difficult and reliable an attack could be, and what impact a successful exploit could have on confidentiality, integrity, and/or availability.
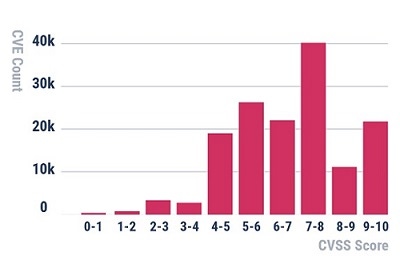
This all makes sense on the surface, but there are some serious technical issues with the rating scheme. Consider this histogram of CVSS base scores for all Common Vulnerabilities and Exposures (CVEs) logged to date:
This is a pretty bizarre breakdown. For any histogram derived from a natural process (that is, what happens in the real world), you'd expect to see a well-known distribution, such as a normal distribution or log-normal distribution. That's especially true when dealing with large data sets (more than 150,000 CVEs have been logged to date).
Note that only a tiny subset of CVEs actually have proof-of-concept exploits ever developed (privately or publicly). So, if we're trying to create a metric that measures risk, we'd expect the proportion of CVEs receiving a 9 or 10 to be very small compared with the other ranges. But in the CVSS distribution of scores, there are more vulnerabilities with scores of 9 or greater than those with values 0–4, combined! Also, why is it that not many scores have a value of 8–9 while many more show up in the 7–8 and 9–10 ranges? That doesn't make much sense. None of these things proves that the CVSS is inaccurate, but it does cast doubt on the rating formula.
However, it's important to not be too critical of the CVSS standardization effort. Since the system was conceived, the number of CVEs reported has grown by about 12% per year, every year, and the world is now in a different place.
CVSS Data as the First Step in Analysis
The CVSS has been a great starting point for the industry, but there are so many details to consider in each category that its overly simplistic formula can no longer provide the level of accuracy we need. The good news: We can still make good use the CVSS as a framework to guide us on where to start our analysis.
Consider the "exploitability" elements of a CVSS 3.1 base score:
Attack Vector (AV)
This essentially captures network-related prerequisites attackers need to satisfy to exploit the flaw. Can they exploit the flaw remotely with no authentication, or does it require attackers to already be running code on a host?
Attack Complexity (AC)
This category is kind of a grab bag of things that make exploitation harder in practice based on a variety of technical considerations.
Privileges Required (PR)
This category captures the access rights needed for exploiting the flaw. It categorizes privileges into "none," "low-privileged user," and "highly privileged user" buckets.
User Interaction (UI)
This element indicates whether an attacker would need to convince a human to perform a specific action for the vulnerability to be exploited. The most common examples are: convincing a user to visit a malicious website or to open an email attachment.
The next step is to relate these items to your own environment. Are there ways we can gather more information in each of these areas to help eliminate false positives or delay fixing issues that are very unlikely to be exploited in your situation?
Suppose you receive a batch of 120 vulnerabilities on Patch Tuesday, where many of those CVEs affect a few thousand systems. Which of those CVEs has a user interface requirement? Probably quite a few. Of the affected machines in your environment, which of them have active users who might be susceptible? For instance, what if you have lots of servers that are listed as vulnerable to some "critical" browser vulnerability, but you know for certain that no one is surfing the Web from those machines? It means that likelihood of exploit is vanishingly small, and you could exclude those from your urgent-priority list. The hard part is to prove it.
One way to do that would be to collect Web browsing usage logs from your proxy or from the individual machines, whip up a few scripts to cross-reference that against vulnerability scanner output, and now you have a repeatable way to deprioritize many instances of a very common category of CVEs.
As another example, consider the case of local-privilege escalation flaws. These can be a very important tool in an attacker's toolbox, but they're only useful if an attacker can gain access to a host to begin with. If a CVE's Privileges Required field is "Low," then you could cross-reference these against the hosts affected and determine if any nonadministrative users (humans or service accounts) have access to the machine. If there are none, then it doesn't seem very likely that the flaw could be used in a successful attack sequence.
This is what we mean by using the CVSS as a framework. You can use the limited information provided in the scoring vector to drive additional environmental data collection and risk estimation based on a superior understanding of the vulnerability in the context of your infrastructure.
The Future of Vulnerability Prioritization
You may wonder what to do with the other elements of a CVSS base score: Scope (S), Confidentiality (C), Integrity (I), and Availability (A). Unfortunately, this is one area where the CVSS starts to break down. After analyzing thousands of CVEs, it quickly becomes clear that trying to estimate the business risk of a CVE in isolation is essentially impossible. Modern networks are far too interconnected for that. Instead, all we can honestly do with individual CVEs is estimate the likelihood that a given vulnerability might be used in attacks based on our understanding of exploitation prerequisites and which vulnerabilities might be more useful to our adversaries.
The current frontier of vulnerability prioritization lies in understanding the interconnections between system configurations, user access rights, network access restrictions; how those relate to your sensitive assets; and how attackers could chain together multiple attacks to gain access to those assets.
Once you're able to do that, you can start to associate specific technical details with the true risk facing a business. This is a hard problem to solve, and automating it will require specialized tools and technologies, but the more we leverage technical context to think about vulnerabilities in terms of their risk to our business, rather than some "fuzzy" notion of technical risk, the better we'll be able to align our vulnerability management programs with what matters most to our organizations — the objective reduction of business risk.
About the Author(s)
You May Also Like
More Insights
Webinars
Key Findings from the State of AppSec Report 2024
May 7, 2024Is AI Identifying Threats to Your Network?
May 14, 2024Where and Why Threat Intelligence Makes Sense for Your Enterprise Security Strategy
May 15, 2024Safeguarding Political Campaigns: Defending Against Mass Phishing Attacks
May 16, 2024Why Effective Asset Management is Critical to Enterprise Cybersecurity
May 21, 2024
Events
Black Hat USA - August 3-8 - Learn More
August 3, 2024Cybersecurity's Hottest New Technologies: What You Need To Know
March 21, 2024