Keep up with the latest cybersecurity threats, newly discovered vulnerabilities, data breach information, and emerging trends. Delivered daily or weekly right to your email inbox.
Securing cloud data is a difficult task on a massive scale. If you don't think you have issues, you probably just can't see them. These steps can help.
4 Min Read
Source: Palo Alto Networks
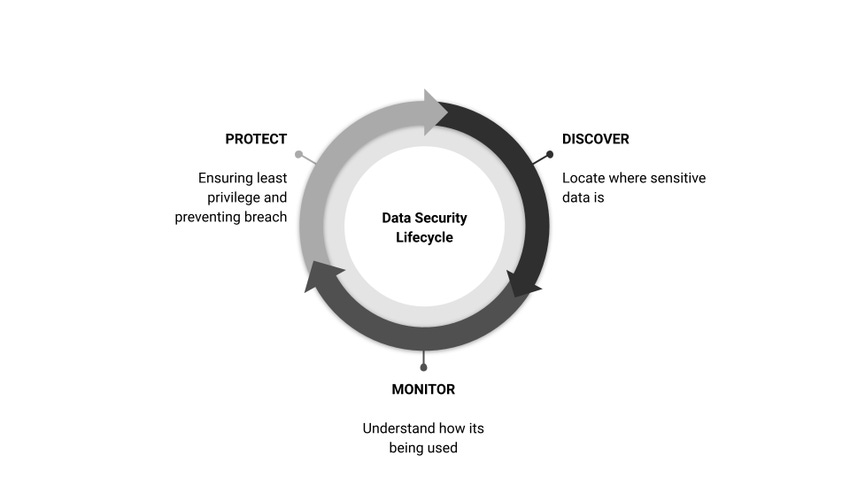
People, process, technology, and data: These are the four key areas that need to be controlled for any successful digital transformation project. The challenge for DevOps, cloud teams, and security professionals when it comes to the cloud is that data proliferates like wildfire. Chalk it up to ease of use, fast deployments, or an overall lack of governance, but many businesses can quickly end up with a tangled web of security and privacy issues. The answer lies in three key practices: discovery, monitoring, and protection.
Discovery
When protecting data, many organizations struggle because they don't have a strong program for tracking it through the lifecycle from creation to destruction. Therefore, the first step in securing data is understanding what you have and where it is.
There are generally two types of data: structured and unstructured. Structured data is usually held in a database and is typically meant to be machine-readable. Unstructured data is typically human-friendly files such as PDFs, Word documents, and the like. For this article, we'll focus on unstructured data.
Tracking unstructured data, at scale, in the cloud, is a daunting task. The best way to begin this process is to understand how data flows into your organization and then disseminates. There is no quick fix to documenting this lifecycle, and depending upon the size of your organization it could take months to execute.
Technology can help, but it's critical that it be wrapped into a larger process to get the best return on investment. While data loss prevention (DLP) solutions have been around for years, when you add cloud into the mix, many options are too complex, too expensive, and resource intensive. That's because there are often separate sets of policies and tools for endpoints, networks, and the cloud.
Bottom line: When performing data discovery, ensure you choose a platform that has a centralized engine, is cloud-delivered, and has a strong road map for machine learning (ML) to help cut down on resource intensity.
Monitoring
Now you need to know how the data is being used and who has access to it. But massive volumes and weak governance make this a significant challenge.
Consider a typical scenario: Jane the developer requests access to datastore X, and the cloud team grants it. In the course of her work, Jane needs to make a copy. Given that it's the cloud, and that she has access, she simply calls an API (no ticket necessary). Ten seconds later, she has a replica of the data. Over the course of the next month, she mistakenly sets permissions incorrectly on the datastore and makes it open to the public Internet. Chaos ensues when it shows up on GrayhatWarfare.
Similar scenarios have played out thousands of times. This is why it's critical to combine data discovery with privilege management. But when the scale reaches a certain level, we begin to reach the extent of what the human mind can grasp. Applying ML models to access security can help teams understand where sensitive data lives, evaluate who has access to it, and determine whether the access patterns are "normal."
Protection
Protection is the end goal of any data security program. Data is what gives much of the modern enterprise its value. Therefore, it must be protected as a bank would guard cash or cryptocurrency.
There are a few powerful ways to protect data after it's been discovered and analyzed. In my view, the most effective is to ensure least privilege is continuously enforced. We talk about this constantly in security precisely because it is difficult to do at scale. So, as in the monitoring phase, we find ourselves looking to ML to help address the problem.
Instead of a team manually sifting through access logs and permissions, an algorithm can look for interesting patterns (or anti-patterns). While every breach looks different, when root cause analysis is carried out, some common indicators of compromise are frequently revealed. These indicators can/should be fed into the algorithm to help train what "interesting" patterns look like. Shifting the laborious process of permission review and access pattern recognition from human to machine will help scale the problem back down.
Situational Awareness
For those on the quest to build a holistic cloud security program, data security is a must. I have personally witnessed many cloud security programs with a complete lack of awareness for the underlying data they were trying to protect. Don't let this be your cloud security program. Focus deeply on continuously discovering the data you have, monitoring how it's being used, and actively protecting it throughout its lifecycle.
 About the Author
About the Author
Matt Chiodi has nearly two decades of security leadership experience and is currently the Chief Security Officer of Public Cloud at Palo Alto Networks. He is a frequent blogger and speaker at industry events such as RSA. He currently leads the Unit 42 Cloud Threat team, which is an elite group of security researchers exclusively focused on public cloud concerns. He is also on faculty at IANS Research.
About the Author(s)
You May Also Like
More Insights
Webinars
Beyond Spam Filters and Firewalls: Preventing Business Email Compromises in the Modern Enterprise
April 30, 2024Key Findings from the State of AppSec Report 2024
May 7, 2024Is AI Identifying Threats to Your Network?
May 14, 2024Where and Why Threat Intelligence Makes Sense for Your Enterprise Security Strategy
May 15, 2024Safeguarding Political Campaigns: Defending Against Mass Phishing Attacks
May 16, 2024
Events
Black Hat USA - August 3-8 - Learn More
August 3, 2024Cybersecurity's Hottest New Technologies: What You Need To Know
March 21, 2024


