



TECH TRENDS
GenAI Tools Will Permeate All Areas of the Enterprise
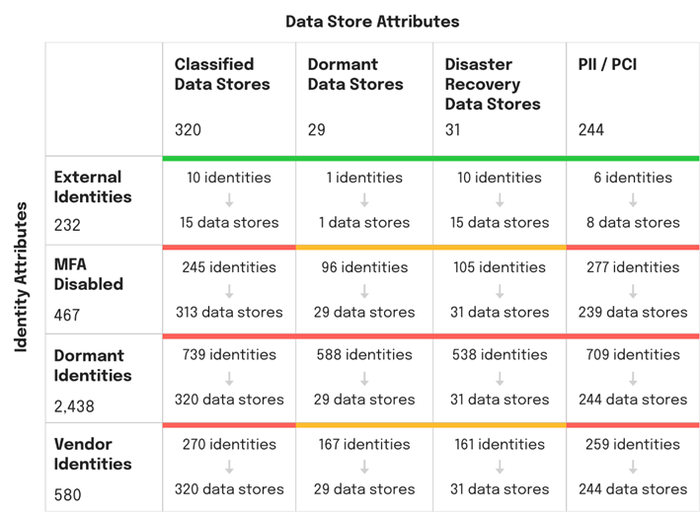
Many departments and groups see the benefits of using generative AI tools, which will complicate the security teams' job of protecting the enterprise from data leaks and compliance and privacy violations.











.jpg?width=100&auto=webp&quality=80&disable=upscale "Picture of Nate Nelson, Contributing Writer")









