

Keep up with the latest cybersecurity threats, newly discovered vulnerabilities, data breach information, and emerging trends. Delivered daily or weekly right to your email inbox.
There’s no simple solution for preventing injection attacks. There <i>are</i> effective strategies that can stop them in their tracks.
8 Min Read
Security is pretty easy, right? If there’s a threat, we put in a defense. Sometimes we can centralize these defenses. For example, you might use an authentication gateway to restrict access to your web applications and web services. Unfortunately, the defenses for "injection” attacks don’t centralize so well, which has made them one of the most popular attack vectors.
Injection: mainlining attacks into your code
Conceptually, injection is simple. It happens any time your code includes untrusted data in a command that is sent to an interpreter. For example, one very popular injection attack can be performed against database interpreters. This attack, known as "SQL Injection" was discovered in 1998 and still pops up in the news every few weeks. SQL Injection happens whenever a developer includes untrusted data in a database query. For example, a developer might take your username and password from a browser request and build a query like this:
The attacker could send in an attack right from his or her browser, with URL parameters designed to modify the meaning of the query. In the example, the query is modified to return every user in the database. In some cases, the attacker could use this attack to steal the entire database or even "own" the database machine.
There are many other varieties including: Command Injection, LDAP Injection, Expression Language Injection, and even Cross-Site Scripting. Almost any component or interface with a command interface is potentially susceptible. Unfortunately, every type of injection has its own unique characteristics, which makes it very difficult to defend against.
Untrusted data and data flow
All these injection attacks come from untrusted data. What data is untrusted? Here’s a simple rule: If you aren’t certain that it doesn’t contain attacks, then it’s untrusted. All the data from the browser, including URL parameters, form fields, headers, and cookies are all untrusted. But so are other sources like flat files, web services, databases, etc… Even internal sources of data can (and probably should) be considered untrusted.
Untrusted data hits an application like a cluster bomb. As this data passes through the millions of lines of application code, libraries, frameworks, and runtime, it gets parsed, copied, split, merged, transformed, assembled, stored, and retrieved. And every copy that is created is a potential injection vector. It can be extremely difficult for both humans and tools to trace all these data flows, which is why many injection flaws get overlooked.
Critical injection defense strategy No. 1: Only process validated data
So, what defense can we drop in to stop injection attacks? Unfortunately, there’s no simple answer. Still, there are two defense strategies that can guide us to prevent any injection flaw.
Most untrusted data comes in the form of a "string" without any restrictions on the size, characters, format, or pattern. Strings are like FedEx One Rate packages for attackers. Even if the developer is trying to ship a ZIP code, temperature, date, or phone number, an attacker can put in whatever he wants and it gets shipped right through your application without inspection.
If you want to validate to prevent injection, you really have to know a lot about the particular interpreter that you are passing data to. For example, if your application is sending untrusted XML to an XML parser, you better know all the details about doctypes, DTDs, and external entities. Almost every interpreter has extensive corner cases and opportunities for an attacker to cause your application to do unexpected things.
A better approach is to parse and validate the data against a specific pattern for what you expect. This is called “positive validation.” In a typical web application or web service with thousands of inputs, this isn’t easy. You’ll need some support from your framework or at least a common validation library so that your validation is consistent. Your mission: Validate all that untrusted input.
But what if your application requires the use of special characters like single-quote, double-quote, hyphen, etc.? Those are exactly the characters that are significant to parsers. So, despite what you might read online, validation shouldn’t be your only defense against injection.
Critical injection defense strategy No. 2: Keep code and data separate
Every CS 101 professor tells students to keep their code and data separate, but that’s easier said than done. What we need is a way to keep the data from getting mixed up with the commands.
Some interpreters provide exactly this sort of interface, called a "parameterized" API. Think of a MadLibs™ game where you fill in the blanks with a particular type of word like verb, adjective, funny bodily sound, etc. The cool thing about MadLibs is that nothing you enter in the blanks can change the template. So, to prevent SQL Injection, you can create a query template, fill in the “parameters” using the API, and then submit the query. If you avoid APIs that take a command as one big string, you can stop injection cold! For example, a parameterized SQL query in Java uses a question mark for the blanks and looks like this:

Unfortunately, not all interpreters have a parameterized API. So how can we keep the code and data separate? We’re going to have to use "escaping" or "encoding." Escaping involves the use of an "escape" character to tell the interpreter that a special character is coming and you should treat it like data and not a command (for example, in JavaScript a quote character). Encoding is similar, except that the special character is translated into a new series of characters, like in a URL using %22 to encode a quote character.
These techniques prevent untrusted data from affecting the meaning of a command. The problem is that the interpreter has its own syntax for escaping and encoding. For example, HTML is probably the worst mashup of code and data of all time, and includes at least five completely different schemes: HTML entity encoding, URL encoding, CSS escaping, JavaScript escaping, and VBScript escaping.
Get ready, developers: You’re going to need to know exactly what characters need to be escaped or encoded and how to do it. There are some libraries available to help you with this, such as the OWASP ESAPI encoders.
Why do I have to both validate and keep data separate?
There are two reasons you need to do both validation and separation. The first is basic defense in depth. Both validation and separation are difficult to get right in all the places they need to be. Doing both helps to minimize gaps and improve your odds of defending attacks.
The second reason is more subtle. Even if your application is totally protected against injection, you should still do validation. Why? Because validation is the only way to detect attacks on your application. Despite the plethora of products on the market claiming to detect application layer attacks, it’s not possible from outside your code. Every application is a beautiful and unique snowflake, so the same string could be completely safe for one and be a complete host takeover for another. Only the application can figure out what input is an attack and what is safe.
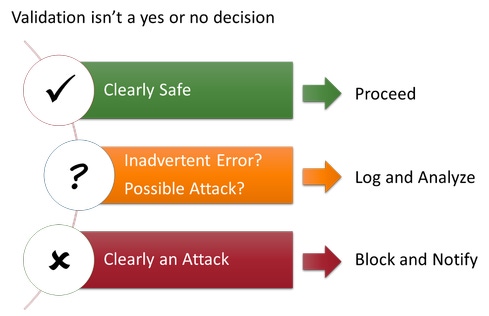
If you think of input validation as a form of intrusion detection, you’ll end up a lot safer. Stopping obvious attacks might be the single most effective thing you could do to protect your application, at least from automated attacks. Your validation should strive to put the data into three different buckets:

If the data exactly matches what you expect, then you can proceed with the data. Don’t forget to use parameterized APIs, encoding, or escaping if you use this data with an interpreter.
If the data is questionable, it might be data that was inadvertently cut-and-pasted into an application, an accidental mistype, or a possible attack. In this case, you want to help your user out and encourage her to submit valid data. But it’s worth keeping an eye on it with logging and periodic analysis.
If the data is clearly an attack, then take action! Don’t just log it and continue. You should probably log out that user and warn her that her account has been compromised (or you could just accuse her of being a hacker). I usually reserve this category for data that could not possibly have been generated by a legitimate user of the application -- for example, a hidden field or pull-down menu value that doesn’t match what was sent to the client. Or, if you have strong client-side validation, you might consider treating any data that doesn’t validate on the server as an attack.
We’ve known about injection attacks for well over a decade. If we keep these two simple strategies in mind, we can stamp out injection and make our software a lot more trustworthy. Let me know in the comments how you handle injection! Good luck.
About the Author(s)
You May Also Like
More Insights
Webinars
The fuel in the new AI race: Data
April 23, 2024Securing Code in the Age of AI
April 24, 2024Beyond Spam Filters and Firewalls: Preventing Business Email Compromises in the Modern Enterprise
April 30, 2024Key Findings from the State of AppSec Report 2024
May 7, 2024Is AI Identifying Threats to Your Network?
May 14, 2024
Events
Black Hat USA - August 3-8 - Learn More
August 3, 2024Cybersecurity's Hottest New Technologies: What You Need To Know
March 21, 2024


